- To make your app scalable, you try to make your app layer “stateless”.
- OK, so you move the "state" out from your application layer out to a shared DB, or shared data layer.
- Now, how do we make the data tier scalable, by definition, we cannot make the data tier stateless.
- OK, now lets think about how to "partition" your data and spread them across multiple machines in such a way that workload is balanced.
- Now there are more boxes and what if some of them crashes.
- OK, we should replicate the data across machines.
- Now, how do we keep these data in sync ...
- And then Cloud computing gets into the picture (as it always does). Now we are not just having a pool of machines but also the pool size can grow and shrink according to workload fluctuation (you don't want to pay for something idle, right ?).
- Now we need to figure out as we add more machines into the pool or remove machine from the pool, how we should "redistribute" the data.
Given an increasing demand of explaining these 2 products recently, I decide to write a post on this.
Not to repeat the basic theory of NOSQL here, for a foundation of distributed system theory underlying the NOSQL design, please refer to my earlier blog
Both Hbase and Cassandra are based on Google BigTable model, here lets introduce some key characteristic underlying Bigtable first.
Fundamentally Distributed
BigTable is built from the ground up on a "highly distributed", "share nothing" architecture. Data is supposed to store in large number of unreliable, commodity server boxes by "partitioning" and "replication". Data partitioning means the data are partitioned by its key and stored in different servers. Replication means the same data element is replicated multiple times at different servers.

Column Oriented
Unlike traditional RDBMS implementation where each "row" is stored contiguous on disk, BigTable, on the other hand, store each column contiguously on disk. The underlying assumption is that in most cases not all columns are needed for data access, column oriented layout allows more records sitting in a disk block and hence can reduce the disk I/O.
Column oriented layout is also very effective to store very sparse data (many cells have NULL value) as well as multi-value cell. The following diagram illustrate the difference between a Row-oriented layout and a Column-oriented layout

Variable number of Columns
In RDBMS, each row must have a fixed set of columns defined by the table schema, and therefore it is not easy to support columns with multi-value attributes. The BigTable model introduces the "Column Family" concept such that a row has a fixed number of "column family" but within the "column family", a row can have a variable number of columns that can be different in each row.

In the Bigtable model, the basic data storage unit is a cell, (addressed by a particular row and column). Bigtable allow multiple timestamp version of data within a cell. In other words, user can address a data element by the rowid, column name and the timestamp. At the configuration level, Bigtable allows the user to specify how many versions can be stored within each cell either by count (how many) or by freshness (how old).
At the physical level, BigTable store each column family contiguously on disk (imagine one file per column family), and physically sort the order of data by rowid, column name and timestamp. After that, the sorted data will be compressed so that a disk block size can store more data. On the other hand, since data within a column family usually has a similar pattern, data compression can be very effective.

Note: Although not shown in this example, rowid of different column families can be completely different types. For example, in the above example, I can have another column family "UserIdx" whose rowid is a string (user's name) and it has columns whose columnKey is the u1, u2 (ie: the row id of the User Column family) and columnValue is null (ie: not used). This is a common technique to build index at the application level.
Sequential write
BigTable model is highly optimized for write operation (insert/update/delete) with sequential write (no disk seek is needed). Basically, write happens by first appending a transaction entry to a log file (hence the disk write I/O is sequential with no disk seek), followed by writing the data into an in-memory Memtable . In case of the machine crashes and all in-memory state is lost, the recovery step will bring the Memtable up to date by replaying the updates in the log file.
All the latest update therefore will be stored at the Memtable, which will grow until reaching a size threshold, then it will flushed the Memtable to the disk as an SSTable (sorted by the String key). Over a period of time there will be multiple SSTables on the disk that store the data.
Merged read
Whenever a read request is received, the system will first lookup the Memtable by its row key to see if it contains the data. If not, it will look at the on-disk SSTable to see if the row-key is there. We call this the "merged read" as the system need to look at multiple places for the data. To speed up the detection, SSTable has a companion Bloom filter such that it can rapidly detect the absence of the row-key. In other words, only when the bloom filter returns positive will the system be doing a detail lookup within the SSTable.
Periodic Data Compaction
As you can imagine, it can be quite inefficient for the read operation when there are too many SSTables scattering around. Therefore, the system periodically merge the SSTable. Notice that since each of the SSTable is individually sorted by key, a simple "merge sort" is sufficient to merge multiple SSTable into one. The merge mechanism is based on a logarithm property where two SSTable of the same size will be merge into a single SSTable will doubling the size. Therefore the number of SSTable is proportion to O(logN) where N is the number of rows.

After looking at the common part, lets look at their difference of Hbase and Cassandra.
HBase
Based on the BigTable, HBase uses the Hadoop Filesystem (HDFS) as its data storage engine. The advantage of this approach is then HBase doesn't need to worry about data replication, data consistency and resiliency because HDFS has handled it already. Of course, the downside is that it is also constrained by the characteristics of HDFS, which is not optimized for random read access. In addition, there will be an extra network latency between the DB server to the File server (which is the data node of Hadoop).
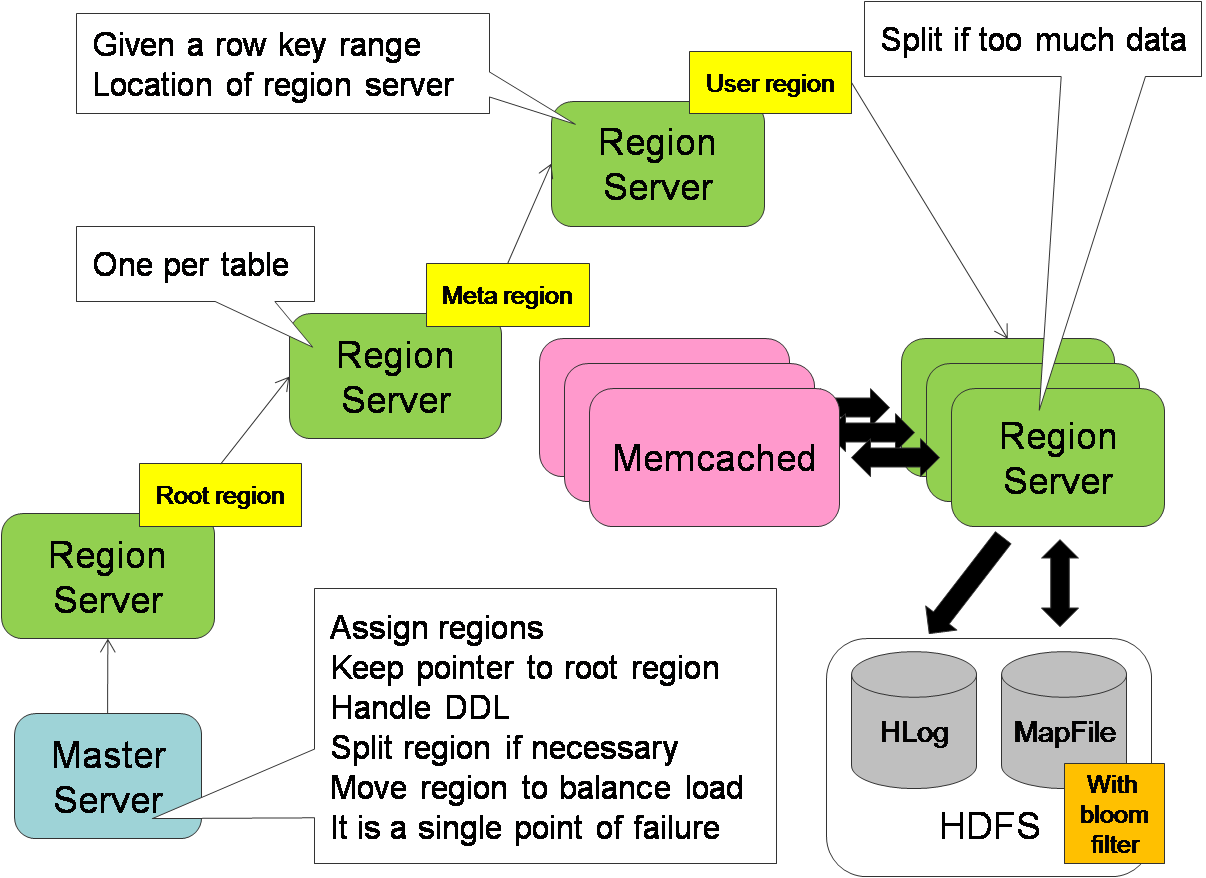
In the HBase architecture, data is stored in a farm of Region Servers. The "key-to-server" mapping is needed to locate the corresponding server and this mapping is stored as a "Table" similar to other user data table.
Before a client do any DB operation, it needs to first locate the corresponding region server.
- The client contacts a predefined Master server who replies the endpoint of a region server that holds a "Root Region" table.
- The client contacts the region server who replies the endpoint of a second region server who holds a "Meta Region" table, which contains a mapping from "user table" to "region server".
- The client contacts this second region server, passing along the user table name. This second region server will lookup its meta region and reply an endpoint of a third region server who holds a "User Region", which contains a mapping from "key range" to "region server"
- The client contacts this third region server, passing along the row key that it wants to lookup. This third region server will lookup its user region and reply the endpoint of a fourth region server who holds the data that the client is looking for.
- Client will cache the result along this process so subsequent request doesn't need to go through this multi-step process again to resolve the corresponding endpoint.
Also in the HBase architecture, there is a special machine playing the "role of master" who monitors and coordinates the activities of all region servers (the heavy-duty worker node). To the best of my knowledge, the master node is the single point of failure at this moment.
For a more detail architecture description, Lars George has a very good explanation in the log file implementation as well as the data storage architecture of Hbase.
Cassandra
Also based on the BigTable model, Cassandra use the DHT (distributed hash table) model to partition its data, based on the paper described in the Amazon Dynamo model.
Consistent Hashing via O(1) DHT
Each machine (node) is associated with a particular id that is distributed in a keyspace (e.g. 128 bit). All the data element is also associated with a key (in the same key space). The server owns all the data whose key lies between its id and the preceding server's id.
Data is also replicated across multiple servers. Cassandra offers multiple replication schema including storing the replicas in neighbor servers (whose id succeed the server owning the data), or a rack-aware strategy by storing the replicas in a physical location. The simple partition strategy is as follows ...

Tunable Consistency Level
Unlike Hbase, Cassandra allows you to choose the consistency level that is suitable to your application, so you can gain more scalability if willing to tradeoff some data consistency.
For example, it allows you to choose how many ACK to receive from different replicas before considering a WRITE to be successful. Similarly, you can choose how many replica's response to be received in the case of READ before return the result to the client.
By choosing the appropriate number for W and R response, you can choose the level of consistency you like. For example, to achieve Strict Consistency, we just need to pick W, R such that W + R > N. This including the possibility of (W = one and R = all), (R = one and W = all), (W = quorum and R = quorum). Of course, if you don't need strict consistency, you can even choose a smaller value for W and R and gain a bigger availability. Regardless of what consistency level you choose, the data will be eventual consistent by the "hinted handoff", "read repair" and "anti-entropy sync" mechanism described below.
Hinted Handoff
The client performs a write by send the request to any Cassandra node which will act as the proxy to the client. This proxy node will located N corresponding nodes that holds the data replicas and forward the write request to all of them. In case any node is failed, it will pick a random node as a handoff node and write the request with a hint telling it to forward the write request back to the failed node after it recovers. The handoff node will then periodically check for the recovery of the failed node and forward the write to it. Therefore, the original node will eventually receive all the write request.
Conflict Resolution
Since write can reach different replica, the corresponding timestamp of the data is used to resolve conflict, in other words, the latest timestamp wins and push the earlier timestamps into an earlier version (they are not lost)
Read Repair
When the client performs a "read", the proxy node will issue N reads but only wait for R copies of responses and return the one with the latest version. In case some nodes respond with an older version, the proxy node will send the latest version to them asynchronously, hence these left-behind node will still eventually catch up with the latest version.
Anti-Entropy data sync
To ensure the data is still in sync even there is no READ and WRITE occurs to the data, replica nodes periodically gossip with each other to figure out if anyone out of sync. For each key range of data, each member in the replica group compute a Merkel tree (a hash encoding tree where the difference can be located quickly) and send it to other neighbors. By comparing the received Merkel tree with its own tree, each member can quickly determine which data portion is out of sync. If so, it will send the diff to the left-behind members.
Anti-entropy is the "catch-all" way to guarantee eventual consistency, but is also pretty expensive and therefore is not done frequently. By combining the data sync with read repair and hinted handoff, we can keep the replicas pretty up-to-date.
BigTable trade offs
To retain the scalability features of BigTable, some of the basic features of what RDBMS has provided is missing in the BigTable model. Here we highlight the rough edges of Bigtable.
1) Primitive transaction support
Transaction protection is only guaranteed within a single row. In other words, you cannot start a atomic transaction to modify multiple rows.
2) Primitive isolation support
While you are reading a row, other people may have modified the same row and update it before you. Your view is not current anymore but your later update can easily wipe off other people's change.
There are many techniques how concurrent update can be isolated, including pessimistic approach like locking or optimistic approach by using vector clock to be the version stamp. But to the best of my understanding, there is no robust test-and-set operation in the BigTable model (this is some getLock mechanism in Hbase which I haven't looked into), my impression is that there is no easy way to check there is no concurrent update happen in between.
Because of this limitation, I think BigTable model is more suitable for those applications where concurrent update to the same row is very rare, or some inconsistency is tolerable at the application level. Fortunately, there are still a lot of applications falling into this bucket.
3) No indexes
Notice that data within BigTable are all physically sorted; by rowid, column name and timestamp. There is no index from the column value to its containing rowid.
This model is quite different from RDBMS where you typically define a table and worry about defining the index later. There is no such "index" concept in BigTable and you need to carefully plan out the physical sorting order of your data layout.
Lacking index turns out to be quite inconvenient and many people using Bigtable ends up building their own index at the application level. This usually results in having a highly denormalized data model with lots of column family who store links to other tables. Any update to the base data need to carefully update these other column family as well. From a performance angle, this is actually better than maintaining index in RDBMS because Bigtable is optimized from writes. However, since it is now the application logic to maintain the index, this can be a source of application bugs.
4) No referential integrity enforcement
As mentioned above, since you are building artificial index at the application level, you need to maintain the integrity of your index as well. This includes update your index when the base data is inserted, modified or deleted. This kind of handling logic is traditionally residing at the RDBMS level, but since BigTable has no such referential integrity concept, this responsibility is now landed on your application logic.
5) Lack of surrounding tools
As NOSQL or BigTable is very new, the tools surrounding it is definitely not comparable to the RDBMS world at this moment, such tools includes report generation, BI, data warehouse ... etc.
I observe the general trend that most NOSQL products are moving towards the direction to provide an ODBC / JDBC interface to integrate with existing tool markets easier. But at this moment, to the best of my understanding, such interface is not wide spread yet.
Design Patterns for Bigtable model
Due to the very different model of Bigtable, the data model design methodology is also quite different from traditional RDBMS schema design. Here is a sequence of steps that are pretty common ...
1) Identify all your query scenarios
Since there is no index concept, you have to plan out carefully how your data is physically sorted. Therefore it is important to find all your query use cases first.
2) Define your "entity table" and its corresponding column families
For an entity table, it is pretty common to have one column family storing all the entity attributes, and multiple column families to store the links to other entities. (e.g. A "UserTable" may contain a column family "baseInfo" to store all attributes of the user, a column family "friend" to store the links to another user, a column family "company" to store links to another CompanyTable)
3) Define your "index table"
The "index table" is what your application build to support reverse lookup. The "key" is typically base on the search criteria you have identified in your query scenario. It is not uncommon that each query may have its own specific index table.
4) Make sure your application logic updates the index correctly
Since the index table has to be maintained by application logic, you need to check to make sure it is done correctly. In many cases, this can be quite a source of bugs.
It is important to realize that NOSQL is not advocating a replacement of RDBMS which has been proven in many lines of application. The NOSQL should be considered a complementary technologies for some niche area where RDBMS is not covering well.
5) Design your update to be idempotent
Max's post has a good articulation on this. The basic idea is that due to the eventual consistency model based on "read/repair" and "quorum update". It is possible that a failed update is in fact successful. Here is how this can happen.
- Client issue a quorum update.
- The server distributed the update to all replica servers, but unfortunately doesn't get more than half to respond successfully. So it returns a failure to the client.
- Nevertheless, the update has been received by some minority replicas (in other words, they don't rollback even the update is not successful).
- Later, if the client read one of this minority, it will get this update (even it has failed). Even more, since this update has a later version, it will read-repair the other copies (ie: further propagate the failed update).