 Hard disk partitioning is almost a must, according to what I have heard so far from my colleagues and other professionals (may be same for you). I am used to partition a hard disk at least to three drives; "C" for OS (Operating System), "D" for programs and "E for other files like documents, archives. But I got a chance to read some material on hard drive performance and it completely argued my partitioning practices.
Hard disk partitioning is almost a must, according to what I have heard so far from my colleagues and other professionals (may be same for you). I am used to partition a hard disk at least to three drives; "C" for OS (Operating System), "D" for programs and "E for other files like documents, archives. But I got a chance to read some material on hard drive performance and it completely argued my partitioning practices.When considering the speed in reading a file from hard drive following are two important points related to partitioning.
1. Files in outer tracks are readable much faster
It is a well known theory in hard disk read/writes that performance is much higher in outer tracks compared to inner tracks.
2. When partitioning a hard disk, the first partition is created in the outer tracks
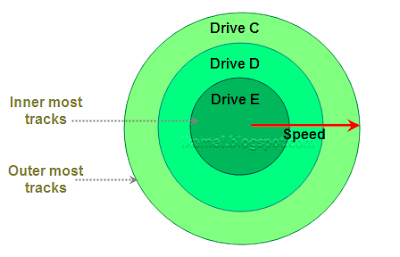
In creating partitions, the first partition is created in the outer most tracks while each new partition is created in inner tracks than the previous. So the partitions in a hard disk would look as the above diagram.
These two are important point to consider. We are creating partitions in order to organize the files according to mentally created categories; like operating system in one partition while program files in another partition. But I did not organize the files in the frequency they are used (which I should have thought of). There are some files frequently used, but placed in different drives without knowing this speed factor. For example; some java projects are stored in drive "E" which I happened to use daily.
So what are the solutions we can think of, in order to achieve the best performance of the hard disk considering these facts? I can think of following two solutions.
1. Create only one partition
One option would be to refrain from creating more than one partition and storing all the files in there. Then we would have to store the most frequently used files in outer tracks while hardly used ones in inner tracks. However this is not that possible, since user is not deciding the location of a file when saving into hard drive. The only solution will be to use a defragmenting software to organize the files later according to the accessing frequency.
2. Store files on partitions according to the frequency of use
We would create a set of partitions same as we used to do earlier, but with a different intension. Files will not be saved in each drive depending on the type or categories, but according to the frequency. The most frequently used files will be stored in drive C while least used files in Drive E. But then again, memorizing the file locations will not be easy.
What is the method are you using in your computers? Do you have any experience in above mentioned suggestions? We welcome your ideas and experiences or any other suggestions.
 In HTML Tables (<table>) there are two attributes named, cellpadding and cellspacing. What is the different between cellpadding and cellspacing? Both these are capable of creating some empty space inside a table.
In HTML Tables (<table>) there are two attributes named, cellpadding and cellspacing. What is the different between cellpadding and cellspacing? Both these are capable of creating some empty space inside a table. What if Michael Phelps is a country himself alone rather than representing United States of America? Michael Phelps has already gathered 8 Gold medals in Beijing Olympics 2008 including 3 relays. Most of the participating countries happened to go back empty hand, so many players are participating knowing they are not up to the level of winning a medal. But consider this man, he's breaking world records in most appearances.
What if Michael Phelps is a country himself alone rather than representing United States of America? Michael Phelps has already gathered 8 Gold medals in Beijing Olympics 2008 including 3 relays. Most of the participating countries happened to go back empty hand, so many players are participating knowing they are not up to the level of winning a medal. But consider this man, he's breaking world records in most appearances. 


 Most wickets by a player in his debut 3-match Test series; a 60+ years old world record has been broken. By whom? By Sri Lankan newly found precious mystery spinner
Most wickets by a player in his debut 3-match Test series; a 60+ years old world record has been broken. By whom? By Sri Lankan newly found precious mystery spinner 

 Do you want to verify whether a Javascript function exists before calling it to avoid runtime errors? With Javascript we used to call Javascript functions. But sometimes our Javascript code tend to throw runtime errors and showing then on the browser. For this there can be several reasons including; incorrect function names or invalid .js file names causing some functions not loaded into your web page.
Do you want to verify whether a Javascript function exists before calling it to avoid runtime errors? With Javascript we used to call Javascript functions. But sometimes our Javascript code tend to throw runtime errors and showing then on the browser. For this there can be several reasons including; incorrect function names or invalid .js file names causing some functions not loaded into your web page. 


